In today’s data-driven world, an effective data pipeline begins with a clear understanding of the business problem it seeks to address. By aligning technical architecture with specific goals, organizations can leverage data to make informed decisions and drive strategic outcomes. Whether the aim is to optimize customer experiences, streamline operations, or guide executive planning, the pipeline and its underlying database architecture should serve as key enablers.
A crucial first step is articulating a well-defined business question. Without clarity on the problem—such as reducing customer churn—even the most advanced technical solutions can fail to yield actionable insights. Identifying the specific metrics and behaviors that influence churn, including engagement levels, support interactions, and purchasing patterns, sets the stage for determining what data is required.
Once the business problem is clear, the next phase involves assessing which data sources are relevant and valuable. In the churn example, data from CRM systems, website analytics, and product usage logs may be necessary. This process calls for discernment: collecting excessive data can complicate workflows, inflate costs, and obscure critical insights. Focusing on data that directly addresses the business question helps maintain efficiency.
Database design is another pivotal aspect. The choice between NoSQL and relational databases, for instance, depends on whether real-time analytics or historical trend analysis is the priority. Proper schema design is essential for ensuring consistency and preventing redundancy, which can undermine scalability and overall pipeline performance. Poorly aligned database structures often lead to operational bottlenecks that compromise data utility.
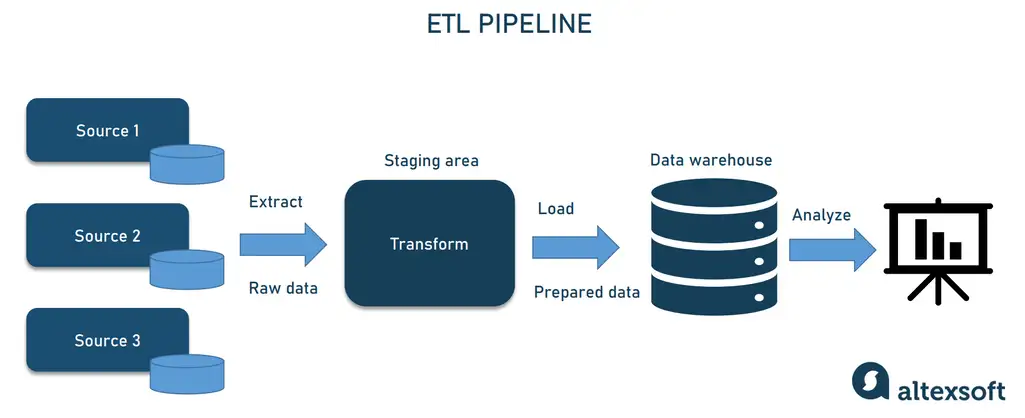
Building a data pipeline that reliably moves information from source to destination requires attention to reliability, scalability, and flexibility. Data must be collected, cleansed, and transformed before it can be stored or analyzed, and tools like Apache Airflow or AWS Glue can automate this orchestration. As business needs evolve, the pipeline should be resilient enough to accommodate new data sources, integration points, and analytic requirements without extensive overhauls.
Once the pipeline is operational, ongoing monitoring is essential. Latency, data quality, and system reliability should be assessed regularly to ensure the solution continues to meet organizational needs. It is equally important to maintain active communication with stakeholders so that emerging requirements are integrated into the pipeline. In a fast-paced environment, iterative improvements help keep the pipeline relevant and effective.
In conclusion, designing a data pipeline and its associated database architecture is inherently tied to understanding the business context. By beginning with a specific problem, choosing relevant data sources, and building an adaptable pipeline, organizations can transform raw information into strategic value. A well-conceived pipeline not only supports immediate decision-making but also stands ready to evolve as new challenges and opportunities arise.
Back to Blog List